
您當(dāng)前位置: 主頁(yè) > 資訊動(dòng)態(tài) > 艾銻分享 >
微軟新作,ImageBERT雖好,千萬級(jí)數(shù)據(jù)集才是亮點(diǎn)
2020-02-05 15:39 作者:
迎戰(zhàn)疫情,艾銻無限用愛與您同行
為中國(guó)中小企業(yè)提供免費(fèi)IT外包服務(wù)

這次的肺炎疫情對(duì)中國(guó)的中小企業(yè)將會(huì)是沉重的打擊,據(jù)釘釘和微信兩個(gè)辦公平臺(tái)數(shù)據(jù)統(tǒng)計(jì)現(xiàn)有2億左右的人在家遠(yuǎn)程辦公,那么對(duì)于中小企業(yè)的員工來說不懂IT技術(shù)將會(huì)讓他們面臨的最大挑戰(zhàn)和困難。
電腦不亮了怎么辦?系統(tǒng)藍(lán)屏如何處理?辦公室的電腦在家如何連接?網(wǎng)絡(luò)應(yīng)該如何設(shè)置?VPN如何搭建?數(shù)據(jù)如何對(duì)接?服務(wù)器如何登錄?數(shù)據(jù)安全如何保證?數(shù)據(jù)如何存儲(chǔ)?視頻會(huì)議如何搭建?業(yè)務(wù)系統(tǒng)如何開啟等等一系列的問題,都會(huì)困擾著并非技術(shù)出身的您。

好消息是當(dāng)您看到這篇文章的時(shí)候,就不用再為上述的問題而苦惱,您只需撥打艾銻無限的全國(guó)免費(fèi)熱線電話:400 650 7820,就會(huì)有我們的遠(yuǎn)程工程師為您解決遇到的問題,他們可以遠(yuǎn)程幫您處理遇到的一些IT技術(shù)難題。
如遇到免費(fèi)熱線占線,您還可以撥打我們的24小時(shí)值班經(jīng)理電話:15601064618或技術(shù)經(jīng)理的電話:13041036957,我們會(huì)在第一時(shí)間接聽您的來電,為您提供適合的解決方案,讓您無論在家還是在企業(yè)都能無憂辦公。
那艾銻無限具體能為您的企業(yè)提供哪些服務(wù)呢?

第一版塊是保障性IT外包服務(wù):如電腦設(shè)備運(yùn)維,辦公設(shè)備運(yùn)維,網(wǎng)絡(luò)設(shè)備運(yùn)維,服務(wù)器運(yùn)維等綜合性企業(yè)IT設(shè)備運(yùn)維服務(wù)。
第二版塊是功能性互聯(lián)網(wǎng)外包服務(wù):如網(wǎng)站開發(fā)外包,小程序開發(fā)外包,APP開發(fā)外包,電商平臺(tái)開發(fā)外包,業(yè)務(wù)系統(tǒng)的開發(fā)外包和后期的運(yùn)維外包服務(wù)。
第三版塊是增值性云服務(wù)外包:如企業(yè)郵箱上云,企業(yè)網(wǎng)站上云,企業(yè)存儲(chǔ)上云,企業(yè)APP小程序上云,企業(yè)業(yè)務(wù)系統(tǒng)上云,阿里云產(chǎn)品等后續(xù)的云運(yùn)維外包服務(wù)。
您要了解更多服務(wù)也可以登錄艾銻無限的官網(wǎng):www.bjitwx.com查看詳細(xì)說明,在疫情期間,您企業(yè)遇到的任何困境只要找到艾銻無限,能免費(fèi)為您提供服務(wù)的我們絕不收一分錢,我們?nèi)w艾銻人承諾此活動(dòng)直到中國(guó)疫情結(jié)束,我們將這次活動(dòng)稱為——春雷行動(dòng)。
以下還有我們?yōu)槟峁┑囊恍┘夹g(shù)資訊,以便可以幫助您更好的了解相關(guān)的IT知識(shí),幫您渡過疫情中辦公遇到的困難和挑戰(zhàn),艾銻無限愿和中國(guó)中小企業(yè)一起共進(jìn)退,因?yàn)槲覀兿嘈湃f物同體,能量合一,只要我們一起齊心協(xié)力,一定會(huì)成功。再一次祝福您和您的企業(yè),戰(zhàn)勝疫情,您和您的企業(yè)一定行。
微軟新作,ImageBERT雖好,千萬級(jí)數(shù)據(jù)集才是亮點(diǎn)
繼 2018 年谷歌的 BERT 模型獲得巨大成功之后,在純文本之外的任務(wù)上也有越來越多的研究人員借鑒了 BERT 的思維,開發(fā)出各種語(yǔ)音、視覺、視頻融合的 BERT 模型。雷鋒網(wǎng) AI 科技評(píng)論曾專門整理并介紹了多篇將BERT應(yīng)用到視覺/視頻領(lǐng)域的重要論文,其中包括最早的VideoBERT以及隨后的ViLBERT、VisualBERT、B2T2、Unicoder-VL、LXMERT、VL-BERT等。其中VL-BERT是由來自中科大、微軟亞研院的研究者共同提出的一種新型通用視覺-語(yǔ)言預(yù)訓(xùn)練模型。繼語(yǔ)言BERT之后,視覺BERT隱隱成為一種新的研究趨勢(shì)。
近期,來自微軟的Bing 多媒體團(tuán)隊(duì)在arXiv上也同樣發(fā)表了一篇將BERT應(yīng)用到視覺中的論文《ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data》
在這篇文章中,作者提出了一種新的視覺語(yǔ)言預(yù)訓(xùn)練模型ImageBERT,并從網(wǎng)絡(luò)上收集了一個(gè)大型的弱監(jiān)督圖像-文本數(shù)據(jù)集LAIT,包含了 10M(1千萬)的 Text-Image pairs,這也是目前最大的一個(gè)數(shù)據(jù)集。利用ImageBERT模型和LAIT數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,在MSCOCO和Flicker30k上進(jìn)行文本到圖像、圖像到文本的檢索任務(wù)上獲得了不錯(cuò)的結(jié)果。
2、背景及相關(guān)工作
隨著Transformer的提出并廣泛應(yīng)用于跨模態(tài)研究,近一年以來,各項(xiàng)任務(wù)上獲得的結(jié)果被推向了一個(gè)新的“珠穆朗瑪峰”。雖然幾乎所有最新的工作都是基于Transformer,但這些工作在不同的方面各有不同。
模型架構(gòu)的維度:
BERT是面向輸入為一個(gè)或兩個(gè)句子的 NLP 任務(wù)的預(yù)訓(xùn)練模型。為了將 BERT 架構(gòu)應(yīng)用于跨模態(tài)任務(wù)中,現(xiàn)在已有諸多處理不同模態(tài)的方法。ViLBERT和LXMERT 先分別應(yīng)用一個(gè)單模態(tài)Transformer到圖像和句子上,之后再采用跨模態(tài)Transformer來結(jié)合這兩種模態(tài)。其他工作如VisualBERT, B2T2,Unicoder-VL, VL-BERT, Unified VLP,UNITER等等,則都是將圖像和句子串聯(lián)為Transformer的單個(gè)輸入。很難說哪個(gè)模型架構(gòu)更好,因?yàn)槟P偷男阅芊浅R蕾囉谥付ǖ膱?chǎng)景。
圖像視覺標(biāo)記維度:
最近幾乎所有的相關(guān)論文都將目標(biāo)檢測(cè)模型應(yīng)用到圖像當(dāng)中,同時(shí)將經(jīng)檢測(cè)的感興趣區(qū)(ROIs) 用作圖像描述符,就如語(yǔ)言標(biāo)記一般。與使用預(yù)訓(xùn)練的檢測(cè)模型的其他工作不同,VL-BERT 結(jié)合了圖像-文本聯(lián)合嵌入網(wǎng)絡(luò)來共同訓(xùn)練檢測(cè)網(wǎng)絡(luò),同時(shí)也將全局圖像特征添加到模型訓(xùn)練中。
可以發(fā)現(xiàn),基于區(qū)域的圖像特征是非常好的圖像描述符,它們形成了一系列可直接輸入到 Transformer 中的視覺標(biāo)記。
預(yù)訓(xùn)練數(shù)據(jù)維度:
與可以利用大量自然語(yǔ)言數(shù)據(jù)的預(yù)訓(xùn)練語(yǔ)言模型不同,視覺-語(yǔ)言任務(wù)需要高質(zhì)量的圖像描述,而這些圖像描述很難免費(fèi)獲得。Conceptual Captions 是最為廣泛應(yīng)用于圖像-文本預(yù)訓(xùn)練的數(shù)據(jù),有 3 百萬個(gè)圖像描述,相對(duì)而言比其他的數(shù)據(jù)集都要大。UNITER 組合了四個(gè)數(shù)據(jù)集(Conceptual Captions,SBU Captions,Visual Genome, MSCOCO),形成了一個(gè)960萬的訓(xùn)練語(yǔ)料庫(kù),并在多個(gè)圖像-文本跨模態(tài)任務(wù)上實(shí)現(xiàn)了最佳結(jié)果。LXMERT將一些VQA訓(xùn)練數(shù)據(jù)增添到預(yù)訓(xùn)練中,并且在VQA任務(wù)上也獲得了最佳結(jié)果。
我們可以發(fā)現(xiàn),數(shù)據(jù)的質(zhì)量和大小對(duì)于模型訓(xùn)練而言至關(guān)重要,研究者們?cè)谠O(shè)計(jì)新的模型時(shí)應(yīng)該對(duì)此給予更大的關(guān)注。
3、數(shù)據(jù)集收集
基于語(yǔ)言模型的BERT,可以使用無限的自然語(yǔ)言文本,例如BooksCorpus或Wikipedia;與之不同,跨模態(tài)的預(yù)訓(xùn)練需要大量且高質(zhì)量的vision-language對(duì)。
目前最新的跨模態(tài)預(yù)訓(xùn)練模型常用的兩個(gè)數(shù)據(jù)集分別是:
The Conceptual Captions (CC) dataset:包含了3百萬帶有描述的圖像,這些圖像是從網(wǎng)頁(yè)的Alt-text HTML屬性中獲取的;
SBU Captions:包含了1百萬用戶相關(guān)標(biāo)題的圖像。
但這些數(shù)據(jù)集仍然不夠大,不足以對(duì)具有數(shù)億參數(shù)的模型進(jìn)行預(yù)訓(xùn)練(特別是在將來可能還會(huì)有更大的模型)。
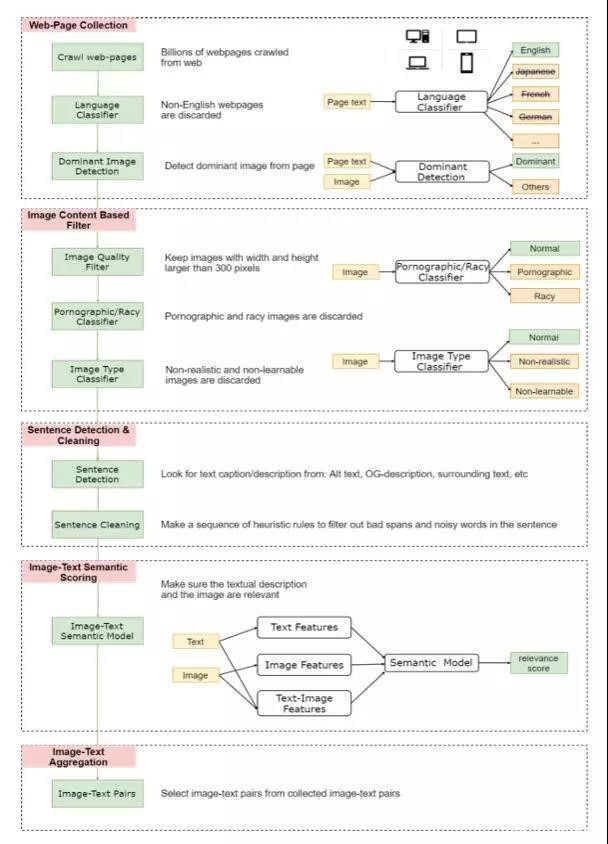
為此,作者設(shè)計(jì)了一種弱監(jiān)督的方法(如下圖所示),從Web上收集了一個(gè)大規(guī)模的圖像文本數(shù)據(jù)集。

弱監(jiān)督數(shù)據(jù)收集流程
先是從網(wǎng)絡(luò)上收集數(shù)億的網(wǎng)頁(yè),從中清除掉所有非英語(yǔ)的部分,然后從中收集圖片的URLs,并利用HTML 標(biāo)記和DOM樹特征檢測(cè)出主要圖片(丟棄非主要圖片,因?yàn)樗鼈兛赡芘c網(wǎng)頁(yè)無關(guān))。
隨后僅保留寬度和高度均大于300像素的圖片,并將一些色情或淫穢內(nèi)容的圖片以及一些非自然的圖片丟棄。
針對(duì)剩下的圖片,將HTML中用戶定義元數(shù)據(jù)(例如Alt、Title屬性、圖片周圍文本等)用作圖像的文本描述.
為了確保文字和圖片在語(yǔ)義上是相關(guān)的,作者利用少量image-text監(jiān)督數(shù)據(jù),訓(xùn)練了一個(gè)弱image-text語(yǔ)義模型來預(yù)測(cè)<text, image>在語(yǔ)義上是否相關(guān)。用這個(gè)模型從十億規(guī)模的image-text 對(duì)中過濾掉相關(guān)性不高的數(shù)據(jù),從而生成的數(shù)據(jù)集LAIT(Large-scale weAk-supervised Image-Text),其中包含了 一千萬張圖片,圖片描述的平均長(zhǎng)度為13個(gè)字。
LAIT數(shù)據(jù)集中的樣本
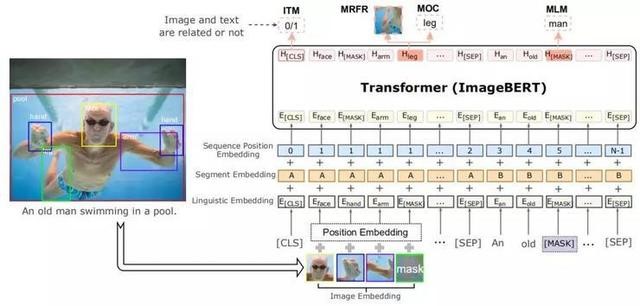
4、ImageBERT模型
如上圖所示,ImageBERT模型的總體架構(gòu)和BERT類似,都采用了Transformer作為最基礎(chǔ)的架構(gòu)。不同之處在于將圖像視覺的標(biāo)記和問題標(biāo)注作為輸入。注意其中圖像視覺標(biāo)記是從Faster-RCNN模型提取的ROL特征。
通過一層嵌入層將文本和圖像編碼成不同的嵌入,然后將嵌入傳送到多層雙自我注意Transformer中來學(xué)習(xí)一個(gè)跨模態(tài)Transformer,從而對(duì)視覺區(qū)域和文字標(biāo)記之間的關(guān)系進(jìn)行建模。
1)嵌入建模
整個(gè)嵌入建模分為三個(gè)部分:語(yǔ)言嵌入、圖像嵌入、序列位置和片段嵌入。
在語(yǔ)言嵌入模塊中采用了與BERT相似的詞預(yù)處理方法。具體而言,是用WordPiece方法將句子分成(標(biāo)記)n個(gè)子詞{w0,...,wn-1}。一些特殊的標(biāo)記,例如CLS和SEP也被增添到標(biāo)記的文本序列里。每個(gè)子詞標(biāo)記的最終嵌入是通過組合其原始單詞嵌入、分段嵌入和序列位置嵌入來生成的。
與語(yǔ)言嵌入類似,圖像嵌入也是通過類似的過程從視覺輸入中產(chǎn)生的。用Faster-RCNN從 o RoIs中提取特征(記為{r0,...ro-1}),從圖像中提取特征,從而讓這兩個(gè)特征代表視覺內(nèi)容。檢測(cè)到的物體對(duì)象不僅可以為語(yǔ)言部分提供整個(gè)圖像的視覺上下文(visual contexts),還可以通過詳細(xì)的區(qū)域信息與特定的術(shù)語(yǔ)相關(guān)聯(lián)。另外,還通過將對(duì)象相對(duì)于全局圖像的位置編碼成5維向量來向圖像嵌入添加位置嵌入。5維向量表示如下:
其中,(xtl,ytl)以及(xbr,ybr)分別代表邊界框的左上角和右下角坐標(biāo)。5維向量中的第五個(gè)分向量相對(duì)于整個(gè)圖像的比例面積。
另外,物體特征和位置嵌入都需要通過語(yǔ)言嵌入投影到同一維度。e(i)代表每個(gè)圖像的RoI。其計(jì)算通過加總對(duì)象嵌入、分段嵌入、圖像位置嵌入以及序列位置嵌入獲得。這意味著每個(gè)嵌入被投影到一個(gè)向量之中,然后用同樣的嵌入大小作為Transformer 隱藏層的尺寸,最后采用正則化層。
在序列位置和片段嵌入中,因?yàn)闆]有檢測(cè)到Rol的順序,所以其對(duì)所有的視覺標(biāo)記使用固定的虛擬位置,并且將相應(yīng)的坐標(biāo)添加到圖像嵌入中。
2)多階段預(yù)訓(xùn)練
不同的數(shù)據(jù)集來源不同,所以其數(shù)據(jù)集質(zhì)量也就不同。為了充分利用不同類型的數(shù)據(jù)集,作者提出了多階段預(yù)訓(xùn)練框架。如下圖所示。
其主要思想是先用大規(guī)模域外數(shù)據(jù)訓(xùn)練預(yù)先訓(xùn)練好的模型,然后再用小規(guī)模域內(nèi)數(shù)據(jù)訓(xùn)練。在多階段預(yù)訓(xùn)練中,為了有順序地利用不同種類的數(shù)據(jù)集,可以將幾個(gè)預(yù)訓(xùn)練階段應(yīng)用到相同的網(wǎng)絡(luò)結(jié)構(gòu)。
更為具體的,在ImageBERT模型中使用兩階段的預(yù)訓(xùn)練策略。第一個(gè)階段使用LAIT數(shù)據(jù)集,第二個(gè)階段使用其他公共數(shù)據(jù)集。注意,兩個(gè)階段應(yīng)使用相同的訓(xùn)練策略。
3)預(yù)訓(xùn)練任務(wù)
在模型預(yù)訓(xùn)練過程中,設(shè)計(jì)了四個(gè)任務(wù)來對(duì)語(yǔ)言信息和視覺內(nèi)容以及它們之間的交互進(jìn)行建模。四個(gè)任務(wù)分別為:掩碼語(yǔ)言建模(Masked Language Modeling)、掩碼對(duì)象分類(Masked Object Classification)、掩碼區(qū)域特征回歸(Masked Region Feature Regression)、圖文匹配(Image-Text Matching)。
掩碼語(yǔ)言建模簡(jiǎn)稱MLM,在這個(gè)任務(wù)中的訓(xùn)練過程與BERT類似。并引入了負(fù)對(duì)數(shù)似然率來進(jìn)行預(yù)測(cè),另外預(yù)測(cè)還基于文本標(biāo)記和視覺特征之間的交叉注意。
掩碼對(duì)象分類簡(jiǎn)稱MOC,是掩碼語(yǔ)言建模的擴(kuò)展。與語(yǔ)言模型類似,其對(duì)視覺對(duì)象標(biāo)記進(jìn)行了掩碼建模。并以15%的概率對(duì)物體對(duì)象進(jìn)行掩碼,在標(biāo)記清零和保留的概率選擇上分別為90%和10%。另外,在此任務(wù)中,還增加了一個(gè)完全的連通層,采用了交叉熵最小化的優(yōu)化目標(biāo),結(jié)合語(yǔ)言特征的上下文,引入負(fù)對(duì)數(shù)似然率來進(jìn)行預(yù)測(cè)正確的標(biāo)簽。
掩碼區(qū)域特征回歸簡(jiǎn)稱MRFR,與掩碼對(duì)象分類類似,其也對(duì)視覺內(nèi)容建模,但它在對(duì)象特征預(yù)測(cè)方面做得更精確。顧名思義,該任務(wù)目的在于對(duì)每個(gè)掩碼對(duì)象的嵌入特征進(jìn)行回歸。在輸出特征向量上添加一個(gè)完全連通的圖層,并將其投影到與匯集的輸入RoI對(duì)象特征相同的維度,然后應(yīng)用L2損失函數(shù)來進(jìn)行回歸。
值得注意的是,上述三個(gè)任務(wù)都使用條件掩碼,這意味著當(dāng)輸入圖像和文本相關(guān)時(shí),只計(jì)算所有掩碼損失。
在圖文匹配任務(wù)中,其主要目標(biāo)是學(xué)習(xí)圖文對(duì)齊(image-text alignment)。具體而言對(duì)于每個(gè)訓(xùn)練樣本對(duì)每個(gè)圖像隨機(jī)抽取負(fù)句(negative sentences),對(duì)每個(gè)句子隨機(jī)抽取負(fù)圖像(negative images),生成負(fù)訓(xùn)練數(shù)據(jù)。在這個(gè)任務(wù)中,其用二元分類損失進(jìn)行優(yōu)化。
4)微調(diào)任務(wù)
經(jīng)過預(yù)訓(xùn)練,可以得到一個(gè)“訓(xùn)練有素”的語(yǔ)言聯(lián)合表征模型,接下來需要對(duì)圖文檢索任務(wù)模型進(jìn)行微調(diào)和評(píng)估,因此本任務(wù)包含圖像檢索和文本檢索兩個(gè)子任務(wù)。圖像檢索目的是給定輸入字幕句能夠檢索正確的圖像,而圖像文本檢索正好相反。經(jīng)過兩個(gè)階段的預(yù)訓(xùn)練后,在MSCoCO和Flickr30k數(shù)據(jù)集上對(duì)模型進(jìn)行了微調(diào),在微調(diào)過程中,輸入序列的格式與預(yù)訓(xùn)練時(shí)的格式相同,但對(duì)象或單詞上沒有任何掩碼。另外,針對(duì)不同的負(fù)采樣方法提出了兩個(gè)微調(diào)目標(biāo):圖像到文本和文本到圖像。
為了使得提高模型效果,還對(duì)三種不同的損失函數(shù)進(jìn)行了實(shí)驗(yàn),這三種損失函數(shù)分別為:二元分類損失、多任務(wù)分類損失、三元組損失(Triplet loss)。關(guān)于這三種微調(diào)損失的組合研究,實(shí)驗(yàn)部分將做介紹。
5、實(shí)驗(yàn)
針對(duì)圖像-文本檢索任務(wù),作者給出了零樣本結(jié)果來評(píng)估預(yù)訓(xùn)練模型的質(zhì)量和經(jīng)過進(jìn)一步微調(diào)后的結(jié)果。下面是在 MSCOCO 和Flickr30k 數(shù)據(jù)集的不同設(shè)置下,對(duì)ImageBERT模型和圖像檢測(cè)和文本檢索任務(wù)上其他最先進(jìn)的方法進(jìn)行的比較。
1)評(píng)估預(yù)訓(xùn)練模型
如前面所提到,模型經(jīng)過了兩次預(yù)訓(xùn)練。首先是在 LAIT 數(shù)據(jù)集上,采用從基于BERT 的模型初始化的參數(shù)對(duì)模型進(jìn)行了預(yù)訓(xùn)練;然后又在公開數(shù)據(jù)集(Conceptual Captions, SBU Captions)上對(duì)模型進(jìn)行二次預(yù)訓(xùn)練。具體過程和實(shí)驗(yàn)設(shè)置請(qǐng)參考論文。
在沒有微調(diào)的情況下,作者在Flickr30k和MSCOCO測(cè)試集上對(duì)預(yù)訓(xùn)練模型進(jìn)行了評(píng)估,如下:
零樣本結(jié)果如表 1 所示,我們可以發(fā)現(xiàn),ImageBERT預(yù)訓(xùn)練模型在MSCOCO 獲得了新的最佳結(jié)果,但在Flickr30k數(shù)據(jù)集上卻比 UNITER模型的表現(xiàn)稍差。
在微調(diào)后,ImageBERT模型獲得了有競(jìng)爭(zhēng)力的結(jié)果,相關(guān)情況在表2 部分進(jìn)行說明。值得一提的是,相比于其他僅有一個(gè)預(yù)訓(xùn)練階段的方法,這種多階段的預(yù)訓(xùn)練策略在預(yù)訓(xùn)練期間學(xué)到了更多有用的知識(shí),因而能夠有助于下游任務(wù)的微調(diào)階段。
2)評(píng)估微調(diào)模型
在檢索任務(wù)上微調(diào)后的最終結(jié)果如表2 所示。我們可以看到,ImageBERT模型在Flickr30k 和 MSCOCO(同時(shí)在 1k和 5k的測(cè)試集)上都實(shí)現(xiàn)了最佳表現(xiàn),并且超越了所有的其他方法,從而證明了本文所提的面向跨模態(tài)聯(lián)合學(xué)習(xí)的 LAIT 數(shù)據(jù)和多階段預(yù)訓(xùn)練策略的有效性。
3)消融實(shí)驗(yàn)
作者也在 Flickr3k 數(shù)據(jù)集上對(duì)預(yù)訓(xùn)練數(shù)據(jù)集的不同組合、全局視覺特征的顯示、不同的訓(xùn)練任務(wù)等進(jìn)行了消融實(shí)驗(yàn),以進(jìn)一步研究ImageBERT模型的架構(gòu)和訓(xùn)練策略。
預(yù)訓(xùn)練數(shù)據(jù)集
作者使用不同數(shù)據(jù)集的組合來進(jìn)行預(yù)訓(xùn)練實(shí)驗(yàn)。結(jié)果如表3所示。CC表示的僅在 Conceptual Captions 數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練;SBU 表示僅在 SBU Captions數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練;LAIT+CC+SBU表示使用LAIT, Conceptual Caption 和 SBU Captions的組合數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練;LAIT → CC+SBU 表示使用 LAIT 來完成第一階段的預(yù)訓(xùn)練,之后使用 Conceptual Captions和SBU Captions 數(shù)據(jù)集來做第二階段的預(yù)訓(xùn)練。
可以看到,用多階段的方法來使用三種不同的域外數(shù)據(jù)集,獲得了比其他方法明顯更好的結(jié)果。
全局圖像特征
值得注意的是,檢測(cè)的ROIs可能并不包含整個(gè)圖像的所有信息。因此,作者也嘗試將全局圖像特征添加到視覺部分。文章使用了三個(gè)不同的CNN 模型(DenseNet,Resnet, GoogleNet)從輸入圖像上提取全局視覺特征,然而卻發(fā)現(xiàn)并非所有的指標(biāo)都會(huì)提高。結(jié)果如表4的第1部分所示。
預(yù)訓(xùn)練損失
作者也將由UNITER引起的MRFR損失添加到預(yù)訓(xùn)練中,結(jié)果在零樣本結(jié)果上獲得略微提高,結(jié)果如表4 的第2 部分所示。這意味著增加一個(gè)更難的任務(wù)來更好地對(duì)視覺內(nèi)容進(jìn)行建模,有助于視覺文本聯(lián)合學(xué)習(xí)。
圖像中的目標(biāo)數(shù)量 (RoIs)
為了理解ImageBERT模型的視覺部分的重要性,作者基于不同的目標(biāo)數(shù)量進(jìn)行了實(shí)驗(yàn)。如表4的第4部分所示,ImageBERT模型在目標(biāo)最少(目標(biāo)數(shù)量與ViLBERT一樣)的情況下,在檢索任務(wù)上并沒有獲得更好的結(jié)果。
可以得出結(jié)論,更多的目標(biāo)確實(shí)能夠幫助模型實(shí)現(xiàn)更好的結(jié)果,因?yàn)楦嗟?RoIs 有助于理解圖像內(nèi)容。
微調(diào)損失
針對(duì)在第4部分所提到的三項(xiàng)損失,作者嘗試在微調(diào)期間進(jìn)行不同的組合。如表4的第4 部分所示,模型通過使用二元交叉熵?fù)p失(Binary Cross-Entropy Loss),本身就能在圖像-文本檢索任務(wù)上獲得最佳的微調(diào)結(jié)果
相關(guān)文章
- [網(wǎng)絡(luò)服務(wù)]艾銻知識(shí) | 2020年值得關(guān)注
- [網(wǎng)絡(luò)服務(wù)]艾銻知識(shí) | 動(dòng)態(tài)路由的鼻
- [桌面服務(wù)]艾銻無限告訴你:Win7系統(tǒng)
- [網(wǎng)絡(luò)服務(wù)]Win7無線Wifi連接不上怎么辦
- [桌面服務(wù)]艾銻無限安全提示:Win7系
- [桌面服務(wù)]艾銻無限告訴您win10關(guān)機(jī)快
- [桌面服務(wù)]艾銻無限告訴您Win7打印機(jī)
- [桌面服務(wù)]北京艾銻無限告訴您:w
- [桌面服務(wù)]北京艾銻無限告訴您:w
- [桌面服務(wù)]北京艾銻無限告訴您:w
- [桌面服務(wù)]艾銻知識(shí) | 微軟自曝 Win
- [桌面服務(wù)]微軟發(fā)布Windows 10 KB453269



 關(guān)閉
關(guān)閉