
艾銻知識 |Oracle連接配置解讀
2020-03-11 20:17 作者:admin
世界疫情的發展將會對中國產生那些影響

在過去的一個多月,中國是世界最大的疫情受災區,受感染的人數和死亡人數是2003年非典的10多倍,這個數據讓全世界震驚,但好在中國的領導者當即立刻,做出了ALL IN的行動,全力以赴的處理這一件事,當舉國上下,所有人的意識,焦點,能量全都聚焦處理這一件事的時候,很快這種靠空氣就能傳播的新型冠狀病毒得到了很好的控制.
近期中國受感染的人數在持續下降,很多地區連續數日新增為零,但萬萬沒想到中國鄰近的一些國家有些人被感染,同時這些國家的領導人沒有能快速反應,導致這幾天在世界迅速的傳播開來,從幾個人擴展到了近萬人的規模,本來只有一兩個國家,但因為人數短時間的增長和流動,現在已經在34個國家和地區傳播開來,這將導致整個世界的經濟降速和減緩,美國硅谷的全球最著名的互聯網公司全部放假在家辦公, 好萊塢的電影業也全部暫停,還有更多的行業在陸陸續續的停止中,這場全球性的疫情將會為世界的經濟帶來巨大的挑戰.
中國從剛開始的疫情輸出國將很快變成疫情的輸入國,所以我們接下來面臨的是更多的封閉性的政策,不然疫情就很難被徹底的控制,前幾天北京新增長的幾個人全是從國外回來的,如果每個國家都開始封閉,都開始停止商業的運作,經濟就會快速下滑,當世界的經濟受到嚴重影響時,中國作為世界第二大經濟體,自然也會受到重創.
受到最大影響的出口,中國向外出口主要有:
1.農產品:以水產品、蔬菜、水果、花卉.畜產品、糧食和食用油籽等為主。
2.通信產品:電子信息與通信技術領域
3.鋼鐵:焦炭.鋼坯.鐵合金.鋼絲及制品等。
4.陶瓷
5.機電
6.服裝.紡織品
7.冶金原料
8.我國高新技術產品出口最多的4 類技術領域是計算機與通信技術、電子技術、生命科學技術、光電技術。
9.汽車零部件
10.能源產品:煤
這些行業是中國的主體行業,有上億的勞動者都在這些行業中,如果產能下降,直接導致的就是員工失業的問題,這將是我們急切需要思考的,如何幫助全球快速控制疫情的擴展,把我們的經驗分享給這些疫情增長比較快的國家,從而讓全球開始互幫互助.
只有全球疫情消失,世界的經濟才能真正的恢復,鐘南山院士說,全球疫情結束可能要到六月,其實他說的非常保守,只有全球所有國家像中國一樣ALL IN 來處理這件事,才有可能六月結束全球疫情,如果不是這樣的話,今年也結束不了,因為它的傳播速度太快了,而且這種病毒它是一種細胞生命體,有生命體的細胞就具備變異的能力,一旦變異將會更難處理.

為什么中國能控制的這么好,大家看看自己的小區和出行就能明白,今天我們艾銻無限有位同事,進地鐵的時候,測出了37度體溫,立刻就被地鐵站準備好的專車送到了醫院全面檢查,當然最后的結果是沒有任何問題,可能是他趕地鐵狂奔后溫度升高的結果,但對于測量體溫的人來說是,寧可錯判一百,也不能放過一個,花點錢,花點時間,都是小事,如果真是因為疏忽大意,最終放進了一個新冠患者,那后果將會不堪設想,這也就是為什么中國能在這么大范圍的國家,這么多人口在疫情發展過程中這么快控制住的原因.也許這就是除中國以外的國家需要學習和效仿的.

之前我分享了八個字,可能很多人不太理解,萬物同體,能量合一,今天的世界將不在是分離的狀態,我們在同一個星球,就像是同一個身體,如果我們身體某個部位出現了問題,就會對全身造成破壞,所以一國有難,全球支援,我們不在是競爭和對立的關系,我們彼此之間如果有競爭也應該是為了讓我們變得更好,我們是合一的整體,只有共同變好,才會讓彼此在這個星球中活的更長,活的更久.

祝福中國,祝福世界,祝福我們這個美麗的星球,讓我們聯合起來,真正的去踐行習主席提出的”人類命運共同體”的愿景,讓我們的世界未來越來越好.
艾銻知識 |Oracle連接配置解讀
安裝ORACLE數據庫軟件,dbca安裝數據庫后,需要配置listener連接數據庫。這里有一些概念比較難理解,記錄一些分析實戰結論。
從連接端講起。
1 連接數據庫的方式
oracle的連接串有幾部分構成,這里就按sqlplus為例,一個完成的連接串遵循下面格式
?
| 1 | sqlplus 用戶名/密碼@主機:端口號/SID 可選as sysdba |
2 listener
使用listener連接需要配置完整連接信息,這里分為兩種連接方式,我們看一個listener的例子:
(帶sid的listener使用netmgr增加listener的datavase services即可出現sid的配置)
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
LISTENER2 = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = iZbp1d4tisi44j6vxze02fZ)(PORT = 1522)) ) SID_LIST_LISTENER2 = (SID_LIST = (SID_DESC = (GLOBAL_DBNAME = gdn1400) (ORACLE_HOME = /fdisk1/oracle1400/base/dbhome_1) (SID_NAME = orcl1400) ) ) ADR_BASE_LISTENER2 = /fdisk1/oracle1400/base LISTENER1 = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = iZbp1d4tisi44j6vxze02fZ)(PORT = 1521)) ) ADR_BASE_LISTENER1 = /fdisk1/oracle1400/base |
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
lsnrctl status listener1 ... Services Summary... Service "orcl1400" has 1 instance(s). Instance "orcl1400", status READY, has 1 handler(s) for this service... Service "orcl1400XDB" has 1 instance(s). Instance "orcl1400", status READY, has 1 handler(s) for this service... The command completed successfully lsnrctl status listener2 ... Services Summary... Service "gdn1400" has 1 instance(s). Instance "orcl1400", status UNKNOWN, has 1 handler(s) for this service... The command completed successfully |
我們在看一個連接串:
?
| 1 | sqlplus sys/password@iZbp1d4tisi44j6vxze02fZ:1521/orcl1400 as sysdba |
注意!:這個服務名必須由listener中的某一個提供,這里listener2的服務名提供的是gdn1400,而listener1沒有提供服務名。那么如何連接數據庫呢?答案就是走listener1的連接會去數據庫中動態的查詢服務名(所以叫做動態連接)
?
|
1 2 3 4 5 |
SQL> show parameter service NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ service_names string orcl1400 |
?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
sqlplus sys/password@iZbp1d4tisi44j6vxze02fZ:1522/gdn1400 as sysdba SQL*Plus: Release 12.1.0.2.0 Production on Thu May 30 20:51:00 2019 Copyright (c) 1982, 2014, Oracle. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options SQL> |
那么tns是什么呢?我們看下這個連接串。
?
| 1 | sqlplus sys/password@iZbp1d4tisi44j6vxze02fZ:1521/orcl1400 as sysdba |
?
| 1 | sqlplus sys/password@tns1400 as sysdba |
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
NSN1522 = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = iZbp1d4tisi44j6vxze02fZ)(PORT = 1522)) ) (CONNECT_DATA = (SERVICE_NAME = gdn1400) ) ) NSN1521 = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = iZbp1d4tisi44j6vxze02fZ)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = orcl1400) ) ) |
?
|
1 2 |
NSN1522, iZbp1d4tisi44j6vxze02fZ, 1522, gdn1400 -----> listener2 NSN1521, iZbp1d4tisi44j6vxze02fZ, 1521, orcl1400 -----> listener1 |
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# sqlplus sys/password@nsn1521 as sysdba SQL*Plus: Release 12.1.0.2.0 Production on Thu May 30 20:58:51 2019 Copyright (c) 1982, 2014, Oracle. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options SQL> # sqlplus sys/password@nsn1522 as sysdba SQL*Plus: Release 12.1.0.2.0 Production on Thu May 30 20:58:55 2019 Copyright (c) 1982, 2014, Oracle. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options SQL> |
艾銻知識 |Oracle中多表關聯批量插入批量更新與批量刪除操作
首先要明白一點,為什么會有批量這一個概念,無非就是數據太多了,在java端把數據查出來然后在按照100-300的批次進行更新太耗性能了,而且寫出來的代碼會非常的臃腫,所謂好的實現是用最少的,最精簡的代碼實現需求,代碼越少,留給自己犯錯誤的機會更少。
還有一個知識點就是多表關聯,對于查詢肯定是可以多表關聯的,其實對于除了查詢之外也是可以進行多表關聯過濾數據的,從而達到在Oracle中查到目標數據即可更新,從而規避規避以往需要單獨查一次數據然后在按照100-300的批次做插入,更新,刪除的操作 。
創建必須的表和序列語句:
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
--創建部門表 dept: CREATE TABLE dept ( deptno NUMBER(2) CONSTRAINT PK_DEPT PRIMARY KEY, dname VARCHAR2(14) , loc VARCHAR2(13) , CREATEDTIME DATE, UPDATEDTIME DATE, CREATEDBY NUMBER(7,0), UPDATEDBY NUMBER(7,0) ) ; --創建員工表 emp: CREATE TABLE emp ( empno NUMBER(4) CONSTRAINT PK_EMP PRIMARY KEY, ename VARCHAR2(10), job VARCHAR2(15), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(2) CONSTRAINT FK_DEPTNO REFERENCES DEPT, CREATEDTIME DATE, UPDATEDTIME DATE, CREATEDBY NUMBER(7,0), UPDATEDBY NUMBER(7,0) ); --創建員工表 emp_copy: CREATE TABLE emp_copy ( empno NUMBER(4), ename VARCHAR2(10), job VARCHAR2(15), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), comm NUMBER(7,2), deptno NUMBER(2), CREATEDTIME DATE, UPDATEDTIME DATE, CREATEDBY NUMBER(7,0), UPDATEDBY NUMBER(7,0) ); --自定義一個序列 create sequence emp_sequence increment by 1 --每次增加幾個,我這里是每次增加1 start with 1 --從1開始計數 nomaxvalue --不設置最大值 nocycle --一直累加,不循環 nocache --不建緩沖區 --插入dept表數據: INSERT INTO dept VALUES(10,'ACCOUNTING','NEW YORK',sysdate,sysdate,123123,123123); INSERT INTO dept VALUES (20,'RESEARCH','DALLAS',sysdate,sysdate,123123,123123); INSERT INTO dept VALUES(30,'SALES','CHICAGO',SYSDATE,SYSDATE,123123,123123); INSERT INTO dept VALUES(40,'OPERATIONS','BOSTON',sysdate,sysdate,123123,123123); --插入emp表數據: INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20,sysdate,sysdate,123123,123123); INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,to_date('20-2-1981','dd-mm-yyyy'),1600,300,30,sysdate,sysdate,123123,123123); INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,to_date('22-2-1981','dd-mm-yyyy'),1250,500,30,SYSDATE,SYSDATE,123123,123123); INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,to_date('2-4-1981','dd-mm-yyyy'),2975,NULL,20,sysdate,sysdate,123123,123123); INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,to_date('28-9-1981','dd-mm-yyyy'),1250,1400,30,SYSDATE,SYSDATE,123123,123123); INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,to_date('1-5-1981','dd-mm-yyyy'),2850,NULL,30,sysdate,sysdate,123123,123123); INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,to_date('9-6-1981','dd-mm-yyyy'),2450,NULL,10,SYSDATE,SYSDATE,123123,123123); INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,to_date('19-4-87','dd-mm-yyyy'),3000,NULL,20,SYSDATE,SYSDATE,123123,123123); INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10,sysdate,sysdate,123123,123123); INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,to_date('8-9-1981','dd-mm-yyyy'),1500,0,30,SYSDATE,SYSDATE,123123,123123); INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,to_date('23-5-87','dd-mm-yyyy'),1100,NULL,20,sysdate,sysdate,123123,123123); INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,to_date('3-12-1981','dd-mm-yyyy'),950,NULL,30,sysdate,sysdate,123123,123123); INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,to_date('3-12-1981','dd-mm-yyyy'),3000,NULL,20,SYSDATE,SYSDATE,123123,123123); INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,to_date('23-1-1982','dd-mm-yyyy'),1300,NULL,10,sysdate,sysdate,123123,123123); |
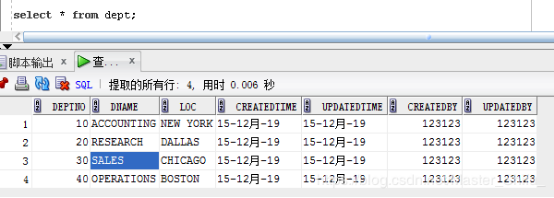
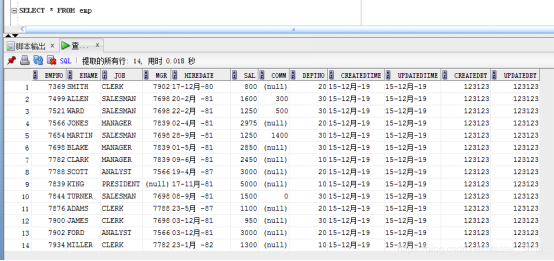
要求:批量復制部門dept表 loc在 CHICAGO的,且工資大于1600的人員信息到emp_copy表,emp_copy的empno需要使用序列emp_sequence
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
INSERT INTO emp_copy SELECT emp_sequence.nextVal,C.* FROM ( SELECT e.ename , e.JOB , e.mgr , e.hiredate, e.sal , e.comm , e.deptno, SYSDATE AS CREATEDTIME, SYSDATE AS UPDATEDTIME, 123124 AS CREATEDBY, 123124 as UPDATEDBY FROM emp e, dept d WHERE e.deptno = d.deptno AND d.loc='CHICAGO' and e.sal>=1500 )C; |
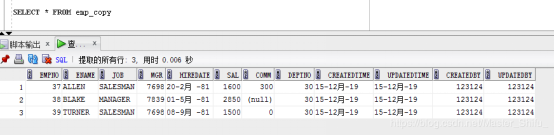
2.多表關聯批量更新
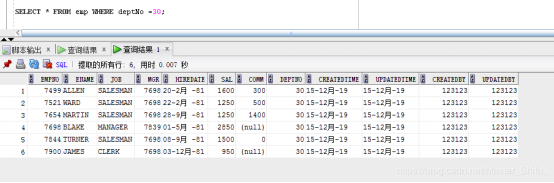
要求:批量更新部門dept表 loc在 CHICAGO的,且職位job為'SALESMAN'的員工,comm在原來基礎上加200
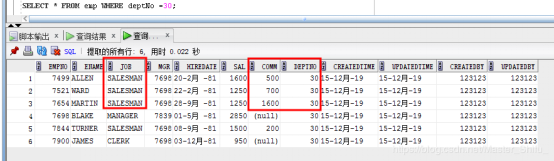
操作之前的數據:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MERGE INTO emp e USING ( SELECT e1.job, e1.ename,e1.comm FROM emp e1, dept d1 WHERE e1.deptno = d1.deptno AND d1.loc='CHICAGO' and e1.job='SALESMAN' )t ON ( e.job = t.job and e.ename = t.ename ) WHEN MATCHED THEN UPDATE set e.comm= t.comm+200 |
3.多表關聯批量刪除
要求:批量刪除部門dept表 loc在 CHICAGO的,且工資小于1500的人員信息
操作之前的數據:
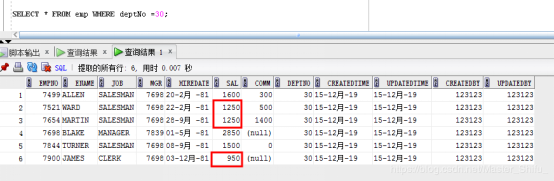
|
1 2 3 4 5 6 7 |
DELETE FROM ( SELECT c.* FROM emp c,dept d WHERE d.deptno = c.deptno AND d.loc = 'CHICAGO' and c.sal < 1500 ); |
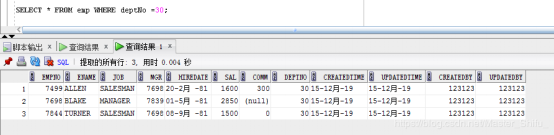
相關文章



 關閉
關閉